
Hasta ahora hemos cubierto la instalación, actualización y algunas configuraciones básicas de Checkmk. En esta tercera entrega vamos a adentrarnos en uno de los aspectos más fundamentales del sistema de monitorización: los chequeos. Concretamente, veremos las diferencias entre chequeos activos y pasivos, cuándo se utiliza cada uno y cómo se comportan en un entorno real.
Comprender esta diferencia no solo es clave para aprovechar al máximo Checkmk, sino también para diseñar una estrategia de monitorización eficaz, escalable y precisa.
¿Dónde se configuran los chequeos activos en Checkmk?
En Checkmk, los chequeos activos son aquellos que el servidor de monitorización ejecuta directamente contra los hosts o servicios. No dependen del agente instalado en el sistema monitorizado, sino que el propio servidor Checkmk inicia la conexión para comprobar si un servicio está disponible o responde correctamente.
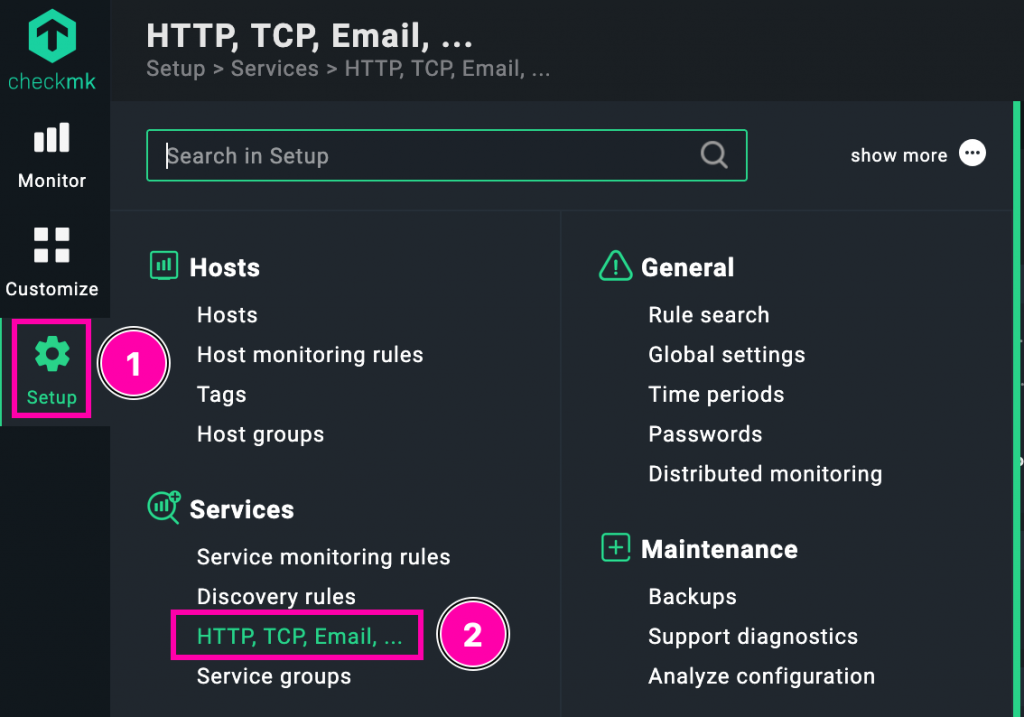
Una gran parte de estos chequeos se configuran desde el siguiente menú:
Setup → Desde aquí accedemos a toda la configuración del sistema.
HTTP, TCP, Email, … → Esta sección incluye chequeos activos predefinidos, como comprobaciones HTTP/HTTPS, puertos TCP abiertos, estado de servidores de correo, servicios DNS, etc.
No obstante, no todos los chequeos activos se encuentran exclusivamente en este apartado. También pueden encontrarse en otras secciones como:
- Plugins específicos: Algunos módulos adicionales (como bases de datos o servicios cloud) añaden chequeos activos propios, que aparecen en sus secciones correspondientes.
- Chequeos SNMP: Aunque SNMP puede utilizarse en modo pasivo (mediante traps), lo habitual es configurarlo como activo, ya que Checkmk interroga al dispositivo de forma periódica para obtener los datos.
A diferencia de los chequeos realizados mediante el cliente (agente de Checkmk), los chequeos activos suelen ser más costosos en términos de recursos. Esto se debe a que cada uno de ellos requiere una conexión de red independiente, ejecución de comandos externos y un análisis individual de resultados. Cuando se monitorizan muchos hosts o servicios con este tipo de chequeos, la carga del sistema y el tráfico de red aumentan significativamente. En cambio, los agentes proporcionan todos los datos necesarios de forma agrupada y eficiente en una única conexión.
Al tratarse de consultas que se lanzan activamente desde el servidor de monitorización, es fundamental ajustar correctamente la frecuencia con la que se ejecutan los chequeos activos. Si se configuran intervalos demasiado cortos, se corre el riesgo de saturar la red o sobrecargar el servicio monitorizado, especialmente si se están haciendo muchas comprobaciones simultáneas. Por el contrario, si se espacian demasiado, se puede perder visibilidad sobre fallos que duran pocos minutos. Encontrar un equilibrio entre precisión y eficiencia es clave para un monitoreo efectivo sin comprometer el rendimiento del sistema ni generar falsos positivos por sobrecarga.
Prueba práctica: Chequeo activo con PING
Para ilustrar cómo funcionan los chequeos activos en Checkmk, vamos a realizar una prueba con uno de los más simples y universales: el chequeo por PING. Este tipo de comprobación se basa en enviar paquetes ICMP al host monitorizado y medir si responde correctamente y cuánto tarda.
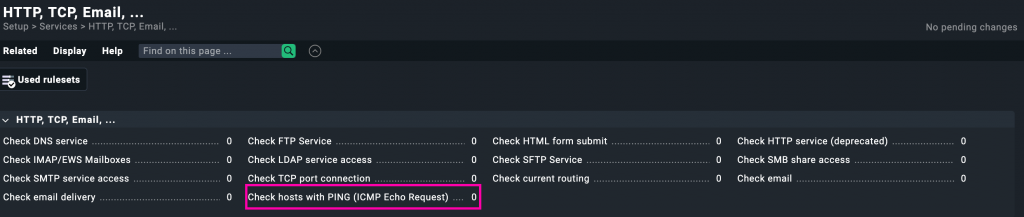
Desde el menú Setup > Services > HTTP, TCP, Email, ..., buscamos la opción «Check hosts with PING (ICMP Echo Request)», como se muestra en la imagen:
Este chequeo nos permite verificar de forma básica si un host está accesible a nivel de red. Es especialmente útil para comprobar la disponibilidad de routers, switches u otros dispositivos que no tienen agente instalado, pero sí responden a paquetes ICMP.
Aunque es muy sencillo, este tipo de chequeo también debe ser usado con precaución: algunos entornos bloquean los paquetes ICMP, lo que puede generar falsos positivos. Además, como cualquier chequeo activo, conviene ajustar la frecuencia con la que se ejecuta para no generar un exceso de tráfico innecesario.
Ajustando los criterios de un chequeo activo: PING personalizado
Aunque podríamos pensar que este tipo de chequeo se aplica a cualquier dirección IP que introduzcamos, lo cierto es que por defecto se ejecuta sobre la dirección IP del host ya configurado en Checkmk, no sobre una IP arbitraria. Además, el resultado del chequeo aparecerá bajo el nombre que definamos en la regla.
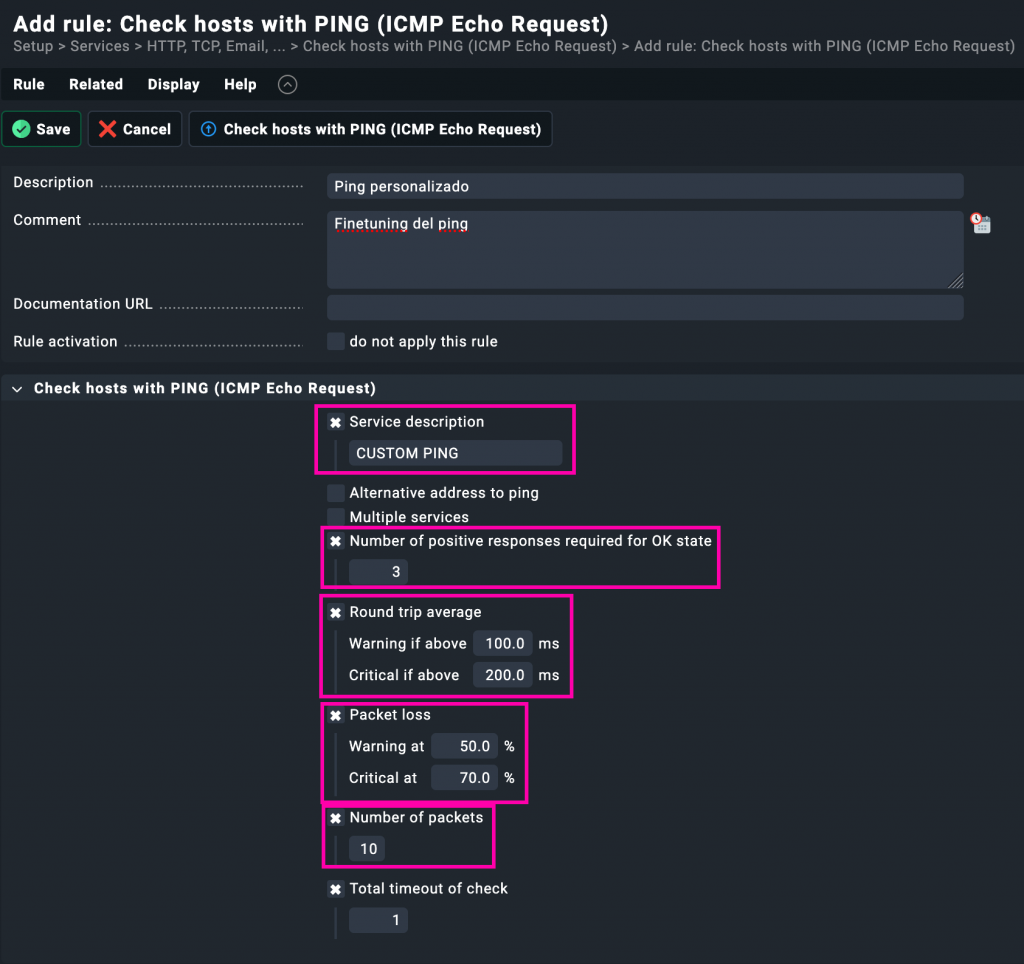
En este ejemplo, hemos creado una regla personalizada para el chequeo por PING en Setup > Services > HTTP, TCP, Email... > Check hosts with PING, con los siguientes ajustes, que podemos ver en la imagen:
- Service description: Hemos llamado al servicio
CUSTOM PING, para diferenciarlo del chequeo por defecto. - Number of positive responses required: Requiere al menos 3 respuestas exitosas para considerarlo correcto.
- Round trip average: Se considera warning si la latencia media supera los 100 ms y critical si pasa de 200 ms.
- Packet loss: Un 50% de pérdida de paquetes genera una advertencia; si supera el 70%, se considera crítico.
- Number of packets: Se envían 10 paquetes ICMP para realizar el test.
- Timeout total del chequeo: El chequeo se cancelará si no se obtiene respuesta en 1 segundo.
Con esta configuración lo que hacemos es endurecer los criterios del chequeo de conectividad. Es decir, el sistema marcará un problema más rápidamente ante síntomas de red inestable o degradada. Esto es útil en entornos donde se requiere una respuesta más sensible a problemas de latencia o pérdida de paquetes, como enlaces críticos o servicios con alta exigencia de disponibilidad.
Para esta prueba hemos decidido aplicar el chequeo activo sobre el mismo servidor donde está instalado Checkmk. Aunque en un entorno real esto no suele ser necesario (ya que el sistema se monitoriza a sí mismo por otros medios), es una buena forma de probar el comportamiento de los chequeos activos y ver los resultados inmediatamente.
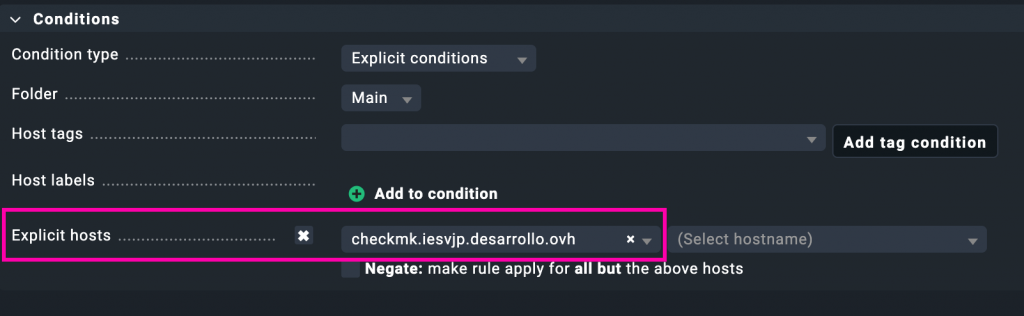
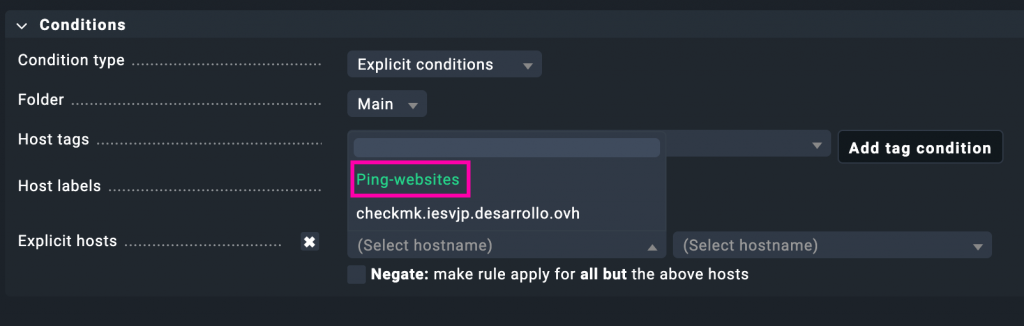
En la sección de condiciones de la regla hemos añadido el host de forma explícita:
Esto garantiza que esta configuración personalizada de ping solo se aplique al host checkmk.iesvjp.desarrollo.ovh. Así evitamos que otros equipos del entorno se vean afectados por estos umbrales más exigentes que hemos definido para la latencia y la pérdida de paquetes.

Salvamos

Activamos configuración
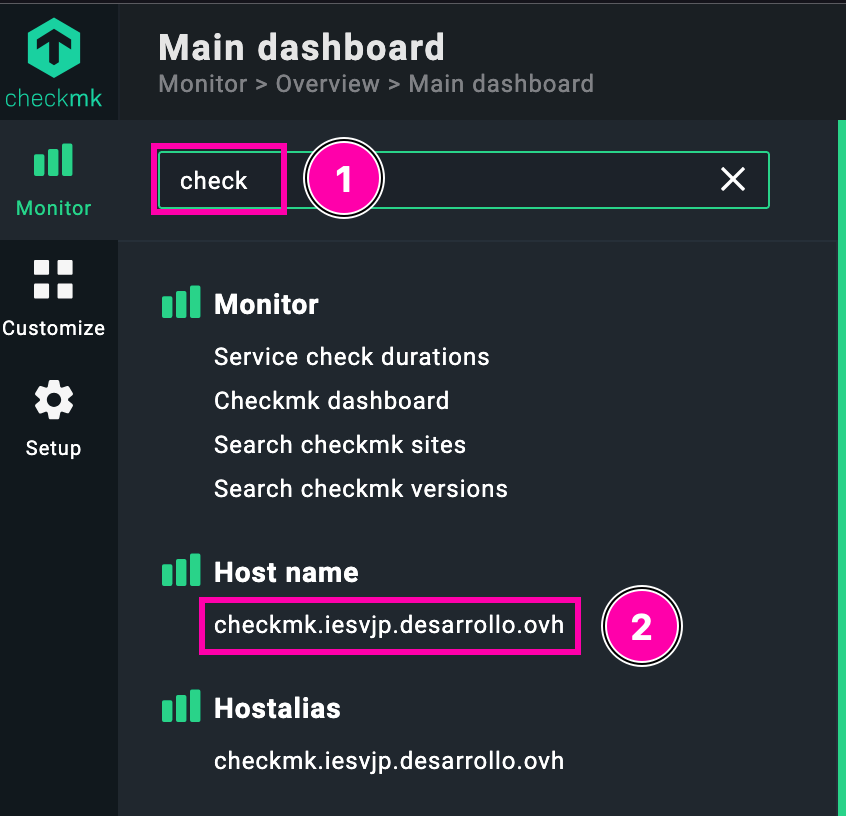
Una vez creada la regla y aplicada al host correspondiente, accedemos al panel de monitorización para ver el resultado. Para ello, desde el Main dashboard, usamos el buscador (1️⃣) para localizar rápidamente nuestro host, en este caso checkmk.iesvjp.desarrollo.ovh (2️⃣), como se muestra en la imagen:
Esto nos lleva directamente a la vista detallada del host, donde podemos comprobar si el nuevo chequeo de CUSTOM PING aparece entre los servicios monitorizados y cómo se comporta bajo los nuevos criterios definidos.
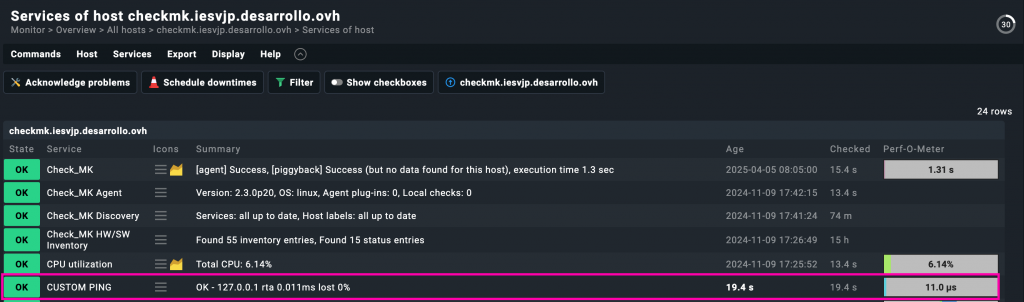
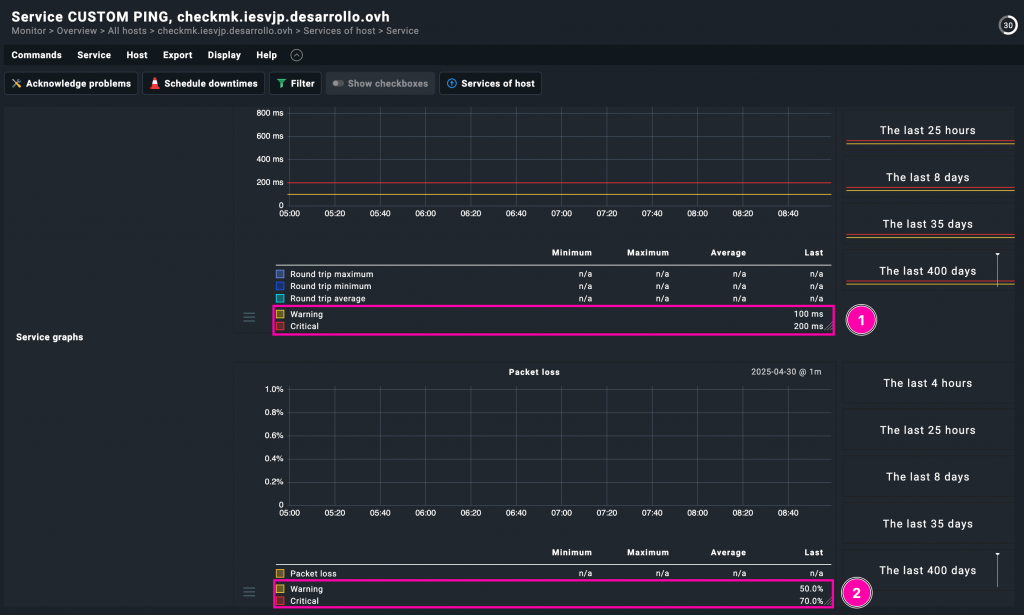
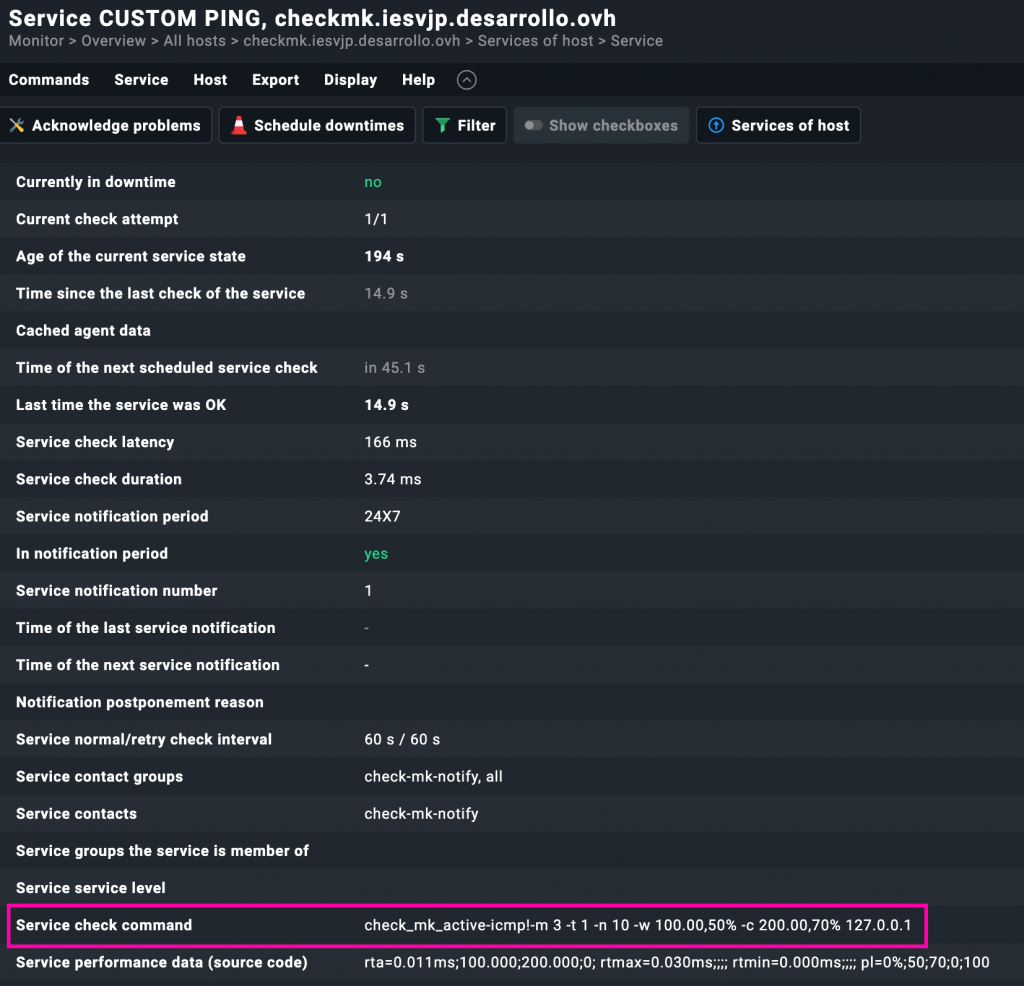
Una vez aplicado el chequeo al host, al entrar dentro del servicio CUSTOM PING podemos ver en detalle cómo se reflejan los parámetros que configuramos previamente.
En la primera imagen se muestran dos gráficas: una para el tiempo medio de respuesta (round trip average) y otra para la pérdida de paquetes (packet loss). Las líneas horizontales marcan los umbrales de advertencia y de estado crítico que definimos (1️⃣ y 2️⃣ respectivamente), confirmando que la regla está activa y funcionando correctamente:
Además, si seguimos bajando en la vista del chequeo, encontramos un resumen detallado de la ejecución. Aquí podemos ver:
- El comando exacto que se está utilizando para realizar el chequeo (con todos los argumentos aplicados, como número de paquetes, umbrales, etc.).
- La dirección IP usada para el ping (en este caso
127.0.0.1, que confirma que el chequeo se hace sobre la IP del host definido). - Otros datos interesantes como la latencia, duración del chequeo, o cuándo fue la última vez que el servicio se reportó como correcto.
Con esto cerramos la prueba de chequeo activo. Hemos demostrado cómo se configura, aplica, visualiza y analiza un servicio de este tipo en Checkmk, lo cual es muy útil para controlar la disponibilidad de hosts de forma directa desde el servidor de monitorización.
Por supuesto, esta prueba tiene un enfoque puramente académico. En un entorno real, hacer un chequeo de ping al propio localhost del servidor de Checkmk tiene poca utilidad práctica, ya que es muy poco probable que este tipo de chequeo falle a menos que haya un problema interno muy específico. Además, si el servidor de Checkmk deja de funcionar, nadie podrá realizarle un chequeo, porque es precisamente quien ejecuta todos los test. Por eso, en producción se recomienda monitorizar Checkmk desde otro nodo externo o emplear mecanismos de alta disponibilidad si se necesita supervisión continua del propio sistema de monitorización.
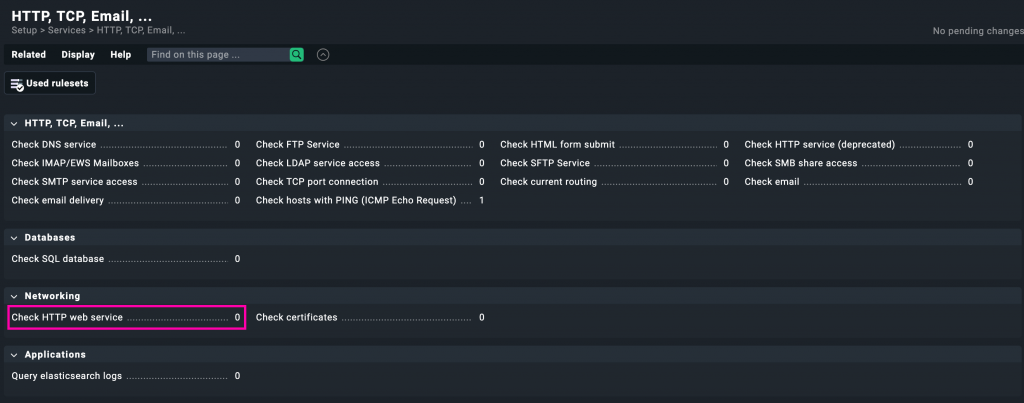
Chequeo activo de servicio web (HTTP)
Ahora que ya hemos realizado una prueba básica con el comando ping, vamos a configurar un chequeo activo más completo y funcional: el monitoreo de un servicio web HTTP. Este tipo de chequeo es muy útil para validar si una web responde correctamente, si devuelve el código esperado (por ejemplo, 200 OK) y si lo hace dentro de un tiempo razonable.
Para ello, accedemos nuevamente a Setup > Services > HTTP, TCP, Email, ... y esta vez seleccionamos la opción Check HTTP web service, como puedes ver en la siguiente imagen:
Este tipo de chequeo es especialmente valioso para monitorizar aplicaciones web, portales corporativos, APIs o cualquier otro servicio que deba estar disponible públicamente. A diferencia del ping, aquí no solo comprobamos conectividad, sino también que el servicio funcione correctamente desde el punto de vista del usuario final.
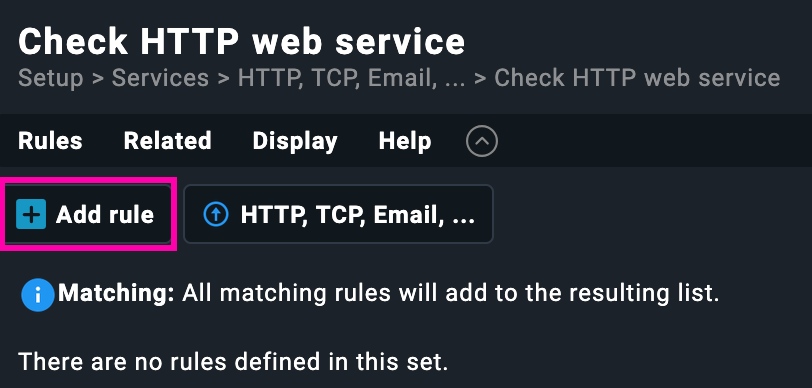
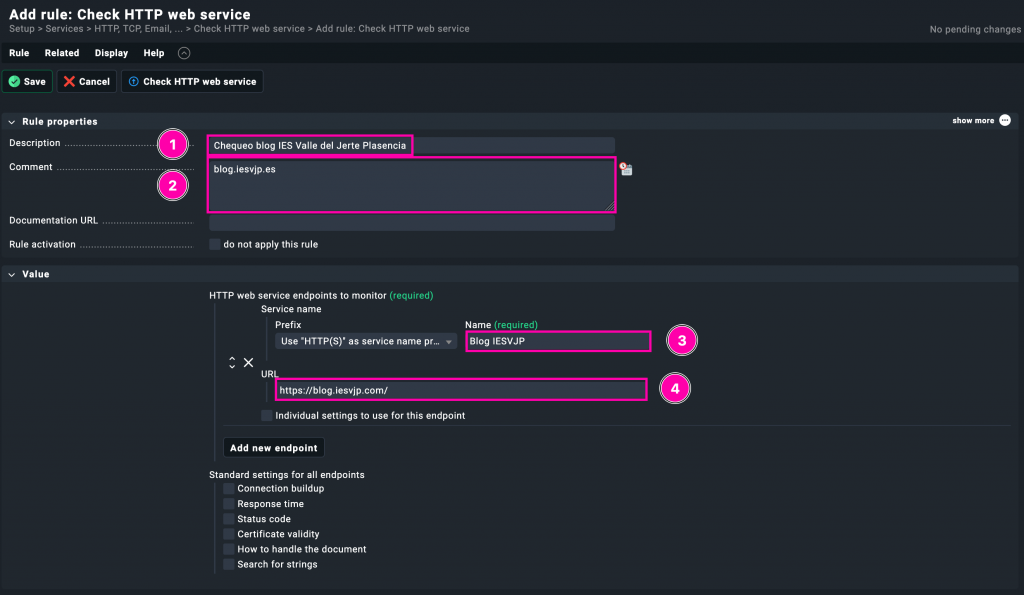
Configurando el chequeo HTTP: blog.iesvjp.com
A modo de ejemplo práctico, vamos a configurar un chequeo activo que valide el funcionamiento del blog del IES Valle del Jerte de Plasencia (https://blog.iesvjp.com). En este caso, no solo queremos saber si la máquina está encendida, sino si el sitio web responde correctamente, con un código HTTP válido y en un tiempo razonable.
En la pantalla de configuración hemos completado los siguientes campos:
1️⃣ Description: Hemos nombrado la regla como Chequeo blog IES Valle del Jerte Plasencia, para identificar fácilmente el propósito del chequeo.
2️⃣ Comment: Indicamos el dominio que vamos a monitorizar, lo que es útil para documentación interna.
3️⃣ Service name: Usamos Blog IESVJP como nombre del servicio que aparecerá en el listado de checks.
4️⃣ URL: Introducimos directamente la URL que queremos comprobar: https://blog.iesvjp.com/. Checkmk se encargará de hacer una petición HTTP(s) y evaluar si el sitio está accesible y responde como se espera.
Este tipo de chequeo es ideal para monitorizar sitios web públicos, y se puede personalizar aún más con opciones como verificar el contenido, comprobar certificados SSL, o establecer umbrales de tiempo de respuesta. Más abajo en esta misma ventana pueden configurarse esas opciones adicionales según el caso.
¿Qué pasa si dejo la condición así?
Aunque parezca que la regla no se aplica a nadie porque no hemos definido hosts explícitos, etiquetas ni labels, en realidad sí se aplicará a todos los hosts contenidos en la carpeta Main.
Y en la mayoría de instalaciones de Checkmk, todos los hosts están dentro de esa carpeta por defecto, ya que Main es la raíz del árbol de carpetas. Por lo tanto:
✅ La regla se aplicará a prácticamente todos los hosts del sistema, salvo que hayas creado carpetas adicionales y movido algunos fuera de Main.
Esto puede llevar a confusión si piensas que dejar la condición «vacía» significa que no afecta a nadie. En realidad, estás aplicando la regla de forma masiva a casi todo el entorno.
Es importante especificar condiciones para los chequeos. Lo vamos a dejar así:
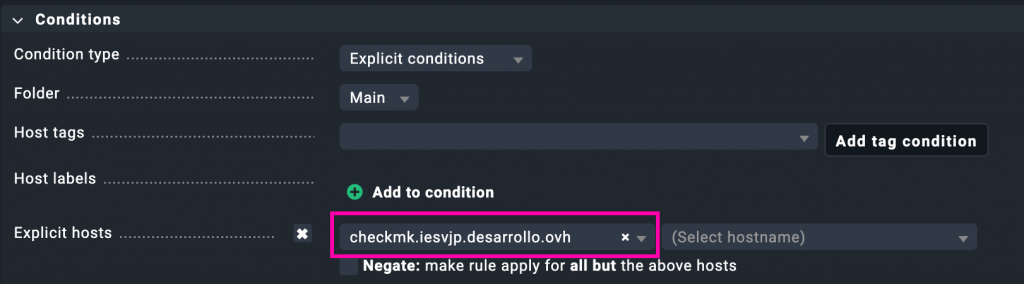
Salvamos, aplicamos cambios…
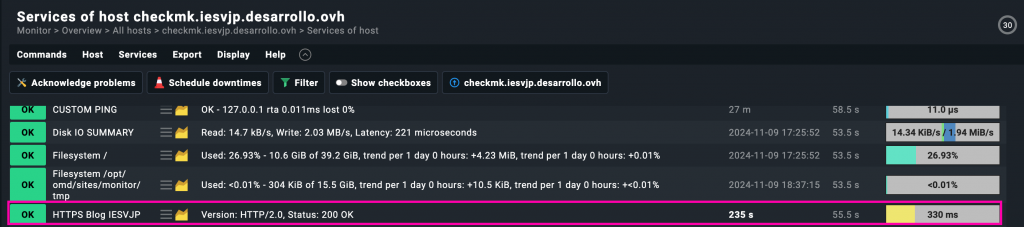
Funciona! pero…
¿Tiene sentido que Checkmk haga un chequeo HTTP a un servidor que no aparece en su lista de servicios?
No, no tiene ninguna lógica. Ordenar los servicios es clave, para esto vamos a crear un host «dummy».
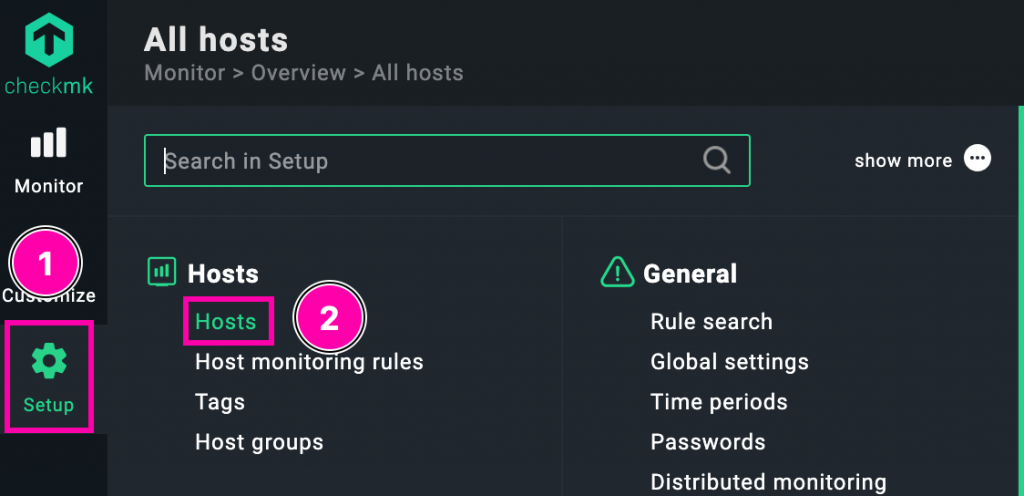
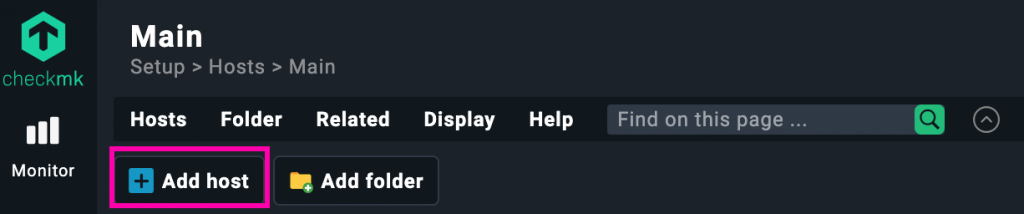
Configuración del host dummy
Al crear el nuevo host, completamos solo los campos necesarios para que Checkmk lo trate como un contenedor lógico para servicios externos, sin agente ni descubrimiento de servicios. En este caso hemos seguido esta configuración:
1️⃣ Host name: Le damos un nombre representativo como Ping-websites, indicando que servirá para monitorizar sitios web externos.
2️⃣ IPv4 address: Usamos una IP ficticia como 127.0.1.1. No se necesita conectividad real, ya que los chequeos no van dirigidos a esta IP, sino a URLs que se definirán en los servicios.
3️⃣ Monitoring agents: Seleccionamos «No API integrations, no Checkmk agent» y «No SNMP», ya que no vamos a instalar ningún agente ni realizar consultas al host.
4️⃣ Labels: Añadimos un label como dummy:host que nos ayudará a identificar o filtrar fácilmente este tipo de hosts especiales dentro del sistema.
5️⃣ Guardar el host: Hacemos clic en «Save & run service discovery», aunque en este caso no encontrará servicios automáticamente. Luego podremos asignarle chequeos manualmente mediante reglas.
No te olvides de activar los cambios!

Con esto, tenemos preparado un host dummy al que podremos asignar cualquier número de chequeos activos como si fuera un contenedor lógico.
Volver a la regla de chequeo HTTP
Una vez creado el host dummy, es momento de regresar a la regla de chequeo que habíamos creado anteriormente, con el fin de reasignarla al nuevo host Ping-websites y dejar de usar el servidor de Checkmk como contenedor de ese servicio.
Para ello:
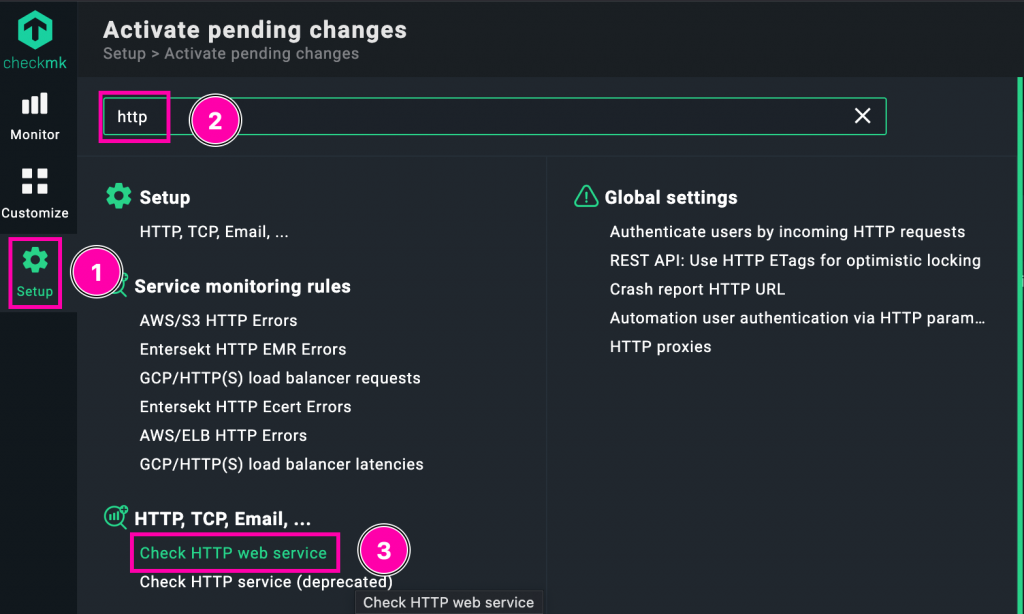
1️⃣ Accede a Setup desde el menú lateral izquierdo.
2️⃣ Escribe http en el buscador superior para filtrar las reglas relacionadas con servicios HTTP.
3️⃣ Haz clic en Check HTTP web service, dentro del grupo «HTTP, TCP, Email, …».
Esto nos llevará al listado de reglas donde podremos localizar la que creamos para blog.iesvjp.com y editar sus condiciones para apuntar al nuevo host dummy.
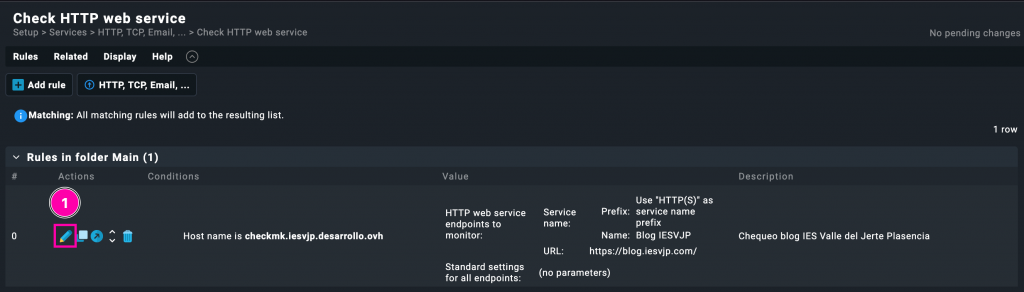
Salvar… Activar…
Verificar el resultado en el nuevo host
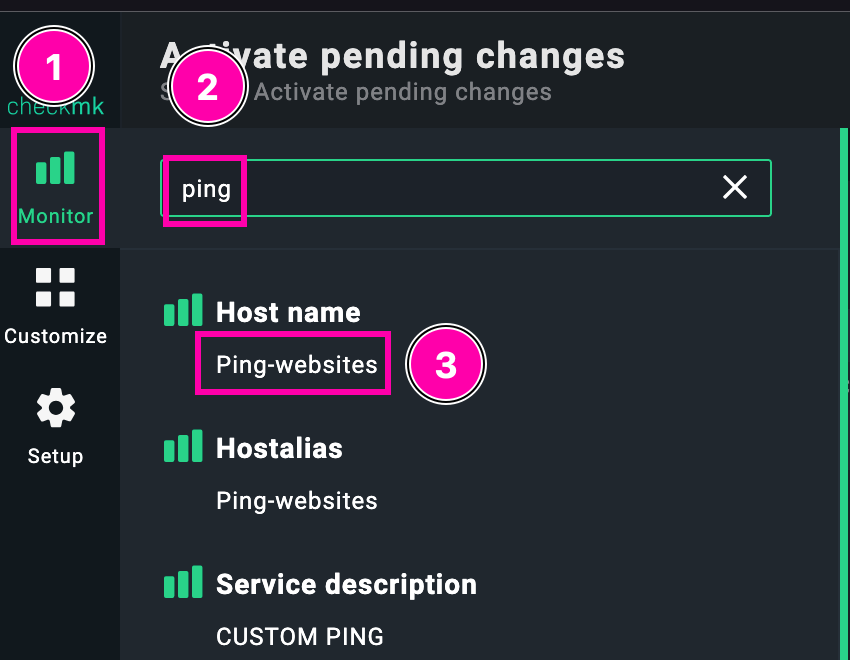
Una vez reasignadas las reglas al host dummy, podemos comprobar que todo se ha aplicado correctamente accediendo al menú de monitorización.
1️⃣ Haz clic en Monitor desde el menú lateral.
2️⃣ Usa el buscador superior escribiendo ping para localizar rápidamente el host y su chequeo activo asociado.
3️⃣ Selecciona el host Ping-websites, donde ya deberían aparecer tanto el chequeo de tipo PING como cualquier otro que se haya trasladado (como el HTTP al blog).
Esto demuestra que ahora los chequeos externos están correctamente separados del servidor principal y organizados dentro de un host específico y coherente.
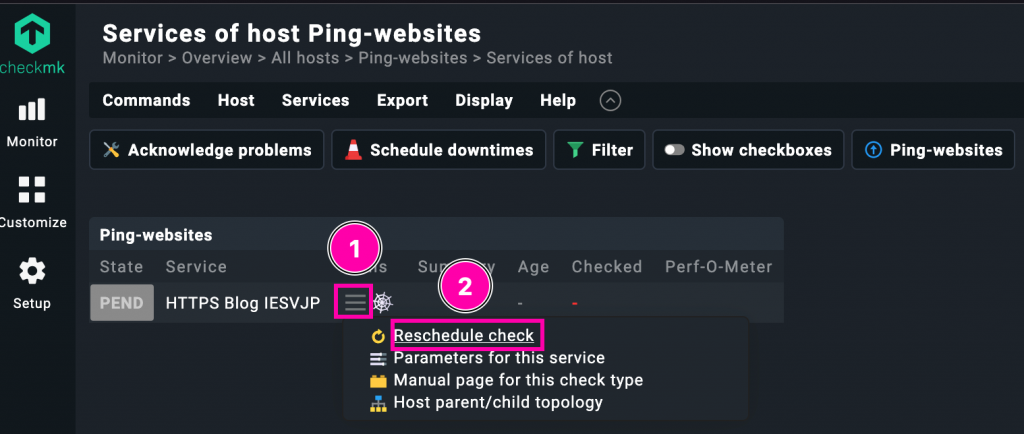
Si eres demasiado rápido y la cola de chequeos no se proceso todavía puedes obligar a ejecutar el check así. Esto no siempre funciona, pero funciona bien con los chequeos activos.
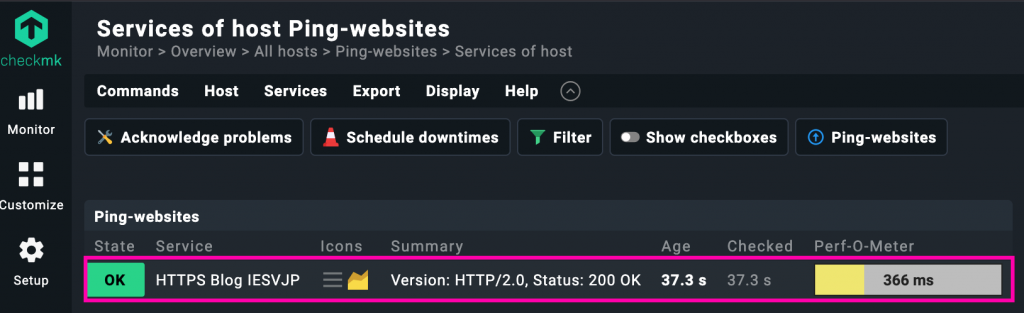
Expandiendo el uso de hosts dummy para chequeos activos
El enfoque de agrupar chequeos activos bajo un host dummy como Ping-websites tiene una ventaja clara: ahora podemos seguir añadiendo más reglas de tipo PING sin necesidad de vincular estos servicios a máquinas reales ni alterar la lógica de monitorización de sistemas productivos.
Pero no tiene por qué quedarse ahí. Puedes crear otros hosts dummy especializados, por ejemplo:
- Uno para chequeos de certificados SSL, donde tendría sentido configurar la frecuencia de comprobación a una vez al día.
- Otro para monitorizar feeds RSS, integraciones externas o endpoints de APIs públicas.
El límite lo marca tu imaginación y tus necesidades, pero es fundamental mantener un orden coherente. Si no clasificas bien los chequeos desde el principio, podrías encontrarte en el futuro con un sistema desorganizado donde localizar un fallo o interpretar un resultado se vuelva confuso… o incluso erróneo, al ver datos en un host que nada tiene que ver con el recurso realmente monitorizado.
Una buena estructura desde el principio es la clave para una monitorización fiable y escalable.
¿Cómo funciona un chequeo activo?
Un chequeo activo consiste en que el propio servidor de Checkmk realiza una consulta directa a un puerto o servicio (como un ping, una conexión HTTP, SMTP, LDAP, etc.) y espera una respuesta. Es Checkmk quien lanza la petición y evalúa el resultado.
En el entorno de Checkmk existen muchos tipos de chequeos activos predefinidos, y puedes combinarlos, personalizarlos o ajustarlos según tus necesidades para cubrir todo tipo de servicios.
Ahora que hemos visto cómo funcionan, pasamos a los que podríamos considerar chequeos pasivos, o más concretamente, chequeos realizados desde el cliente.
Entonces…
¿Dónde se configuran los chequeos pasivos en Checkmk?
Bueno, hay buenas y malas noticias.
La buena noticia es que los chequeos pasivos no requieren que configures uno por uno cada servicio. En realidad, se trata de un grupo de comprobaciones que realiza automáticamente el agente de Checkmk instalado en la máquina destino. Este agente escucha por el puerto 6556 y, al ser consultado por el servidor, devuelve toda la información disponible de una sola vez.
La mala noticia —si es que puede considerarse así— es que no puedes configurar estos chequeos uno a uno desde la interfaz como en los activos. El cliente recoge de forma automática métricas de muchos servicios del sistema (uso de CPU, memoria, discos, procesos, servicios del sistema, etc.), y simplemente los muestra en el panel al hacer el escaneo de servicios.
En resumen: no los defines, se detectan. Esta última frase es falsa en parte, luego lo veremos.
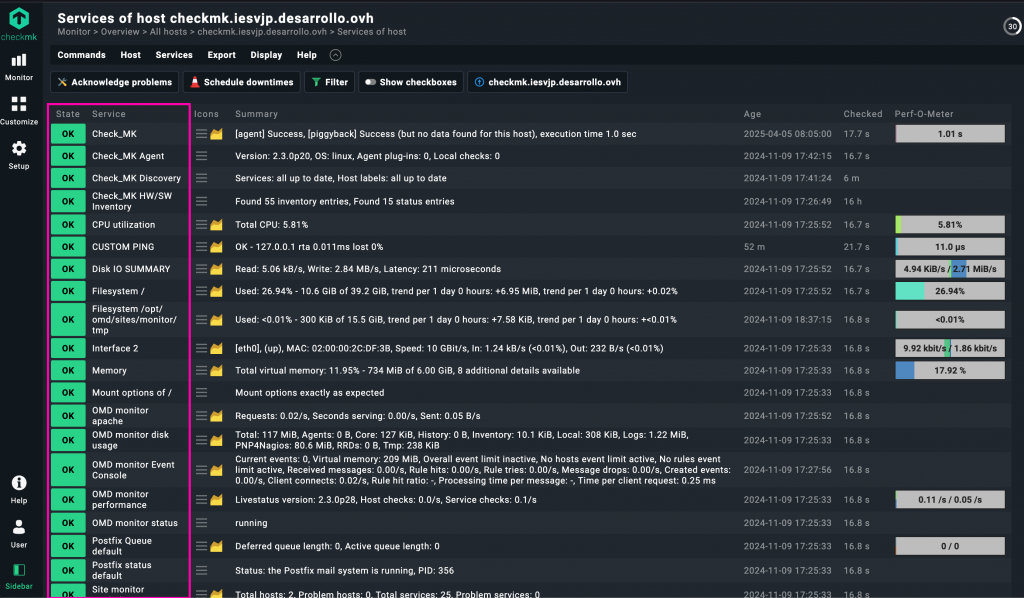
En otro de los tutoriales configuramos correctamente un cliente de Checkmk en un servidor —en este caso, el propio servidor donde está instalado Checkmk—. El resultado es el que ves en la imagen: una lista de servicios que aparecen automáticamente.
¿Lo interesante?
No hemos activado manualmente ninguno de estos chequeos. Simplemente, al instalar y configurar el cliente (y especialmente al establecer la conexión segura mediante SSL), Checkmk empieza a recoger datos que el agente exporta por el puerto 6556.
Estos servicios incluyen métricas del sistema, uso de disco, memoria, red, procesos, servicios como Apache o Postfix, etc. Todo esto se autodetecta y se muestra directamente en el panel tras ejecutar el descubrimiento de servicios.
¿Y si no quiero que aparezcan algunos de ellos?
Durante el descubrimiento
Cuando ejecutas el service discovery, puedes desmarcar manualmente los servicios que no te interesen antes de guardar los cambios. Esto evita que se añadan al monitoring aunque hayan sido detectados.
Con reglas de ignorado (ignore services)
Puedes usar expresiones regulares para excluir servicios por su nombre. Por ejemplo:
^Filesystem /opt→ Ignora los filesystem montados en/opt^Memory→ Ignora todos los chequeos de memoria
Esto es ideal si quieres aplicar esa exclusión de forma automática y consistente en múltiples hosts. Ya se cubrió en otro de los tutoriales.
Ambos métodos son compatibles, y lo ideal es usarlos según el contexto:
✅ Para casos puntuales, el filtrado manual durante el discovery es suficiente.
✅ Para exclusiones más amplias o permanentes, la regla basada en nombre o patrón es la mejor solución.
¿Pero y si no quiero autodiscover ni tampoco active checks? ¿Y si lo que hay no me vale? La manera mas sencilla serían los local checks.
¿Qué son los local checks?
Son scripts que tú mismo puedes escribir en el lenguaje que prefieras (bash, Python, Perl, PowerShell…), que se ejecutan en el cliente, no en el servidor de Checkmk. Estos scripts generan un resultado en un formato muy específico que el agente de Checkmk entiende y envía al servidor.
Ventajas clave de los local checks
- Total libertad: puedes medir lo que quieras, como quieras.
- Fácil integración: no necesitas programar en Python ni seguir la estructura interna de los plugins de Checkmk.
- Sincronización automática: si están bien ubicados, se ejecutan automáticamente con cada ejecución del agente.
- Escalables: puedes crear tantos servicios como líneas genere tu script.
- Potentes: admiten métricas, umbrales dinámicos, múltiples valores, caché, multisalida y más.
¿Por qué no hay que conformarse solo con los chequeos autodetectados o activos?
Porque muchas veces tienes necesidades específicas que Checkmk no cubre directamente (por ejemplo, conteo de procesos concretos, un scraping de una API interna, o un log personalizado). Con los local checks, tú decides qué se mide, cómo se interpreta, y cuándo se ejecuta.
Ejemplo muy básico

#!/bin/bash
echo '0 "Demo service" - Everything is working fine!'0 → Estado del servicio (0=OK, 1=WARNING, 2=CRITICAL, 3=UNKNOWN)
"Demo service" → Nombre que se verá en la interfaz
- → No se envía ninguna métrica
Everything... → Mensaje que aparece como resumen del estadoVamos a crearlo de verdad en el host de checkmk.
nano /usr/lib/check_mk_agent/local/demo_check.sh
chmod +x /usr/lib/check_mk_agent/local/demo_check.sh
Y donde se ejecuta esto? vamos a probar con check_mk_agent. Al final veremos algo parecido a esto:
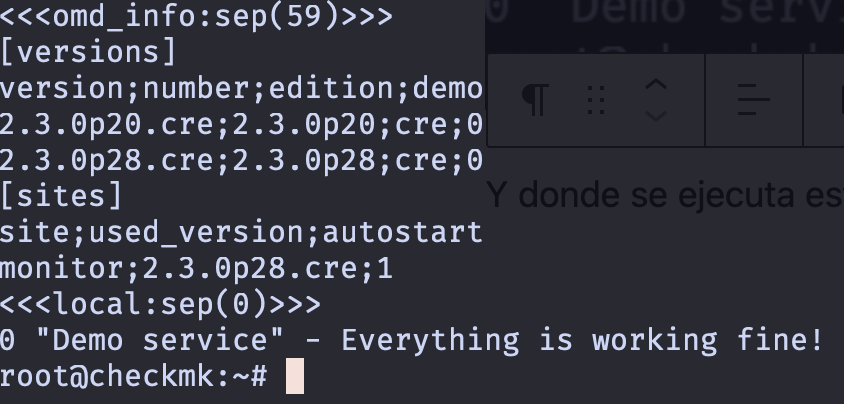
El problema esta en que esto todavía no se ve reflejado en checkmk. Para eso tenemos que ir a:
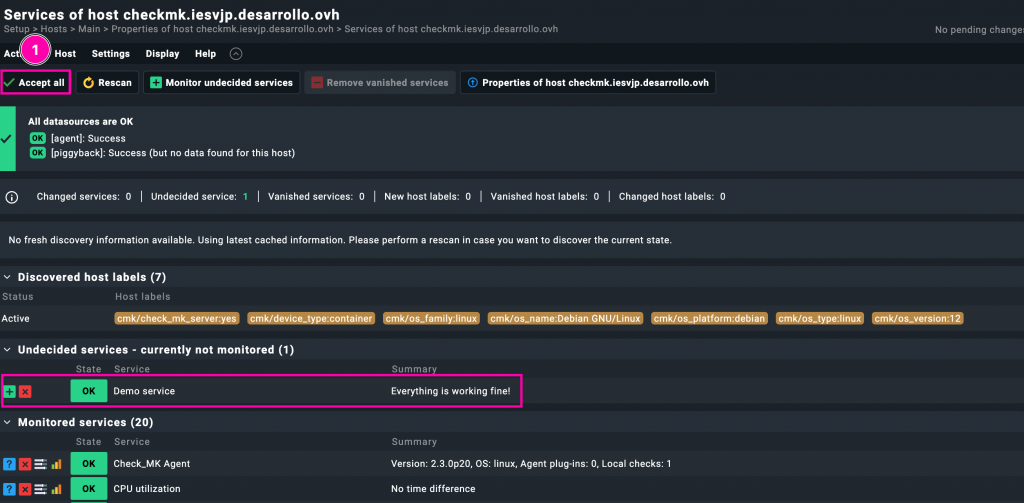
O bien le damos a «Accept all» (en este caso) o bien a +. Esperamos, aplicamos configuración…
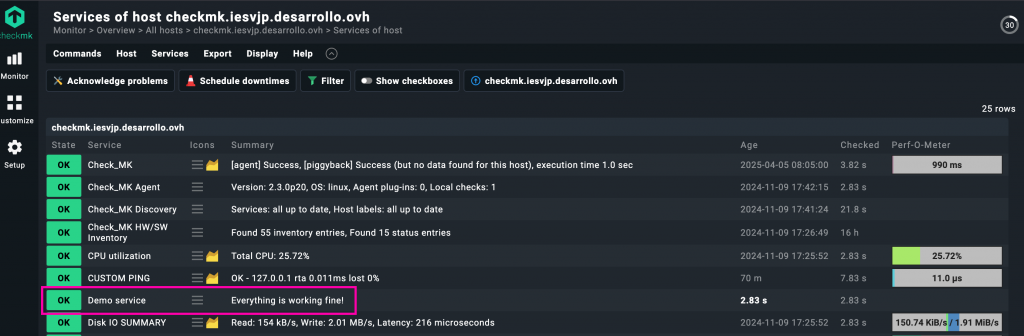
Y ahí lo tenemos.
Este ejemplo tan simple —aunque no tenga utilidad práctica real— demuestra la enorme potencia de los local checks en Checkmk. Lo que acabamos de hacer es solo una prueba estática, pero podrías haber usado cualquier lenguaje: bash, Python, Perl, Go, PowerShell, incluso un binario compilado. Lo único que importa es que el script devuelva una línea de texto con el formato correcto.
Con un único script puedes:
- Definir múltiples servicios (tantas líneas como salidas tenga el script).
- Añadir métricas automáticamente graficables por Checkmk.
- Incluir varias métricas en un solo check, separadas con
|. - Configurar umbrales estáticos o dinámicos para cambiar el estado del servicio según valores.
- Usar disparadores superiores e inferiores, muy útiles en valores con rangos aceptables.
- Mostrar valores con unidades reconocidas (como %, MB, ms…), que se representan correctamente.
- Ejecutar el script de forma asincrónica y con caché, ideal para tareas pesadas o lentas.
En resumen: cualquier cosa que tu máquina pueda medir o calcular se puede convertir en un servicio de Checkmk. Desde usuarios conectados, temperatura de una Raspberry Pi, hasta el número de mensajes en una cola de RabbitMQ. No hay límites más allá de lo que seas capaz de programar.
Algunos ejemplos realmente útiles que puedes implementar con local checks son: comparar la versión actual de un script o app con la última disponible en GitHub, consultar una API de Proxmox Backup Server para verificar si se han hecho los backups del día, comprobar el estado de repositorios de Borg, hacer chequeos personalizados de discos duros SMART, del estado de RAIDZ en ZFS, monitorizar contenedores Docker en ejecución o parados, y prácticamente cualquier información accesible por un comando, archivo o API. Todo esto con la ventaja de que no necesitas escribir plugins complejos ni usar formatos complicados: si puedes generar una línea de texto con los datos y el formato correcto, puedes integrarlo en Checkmk.
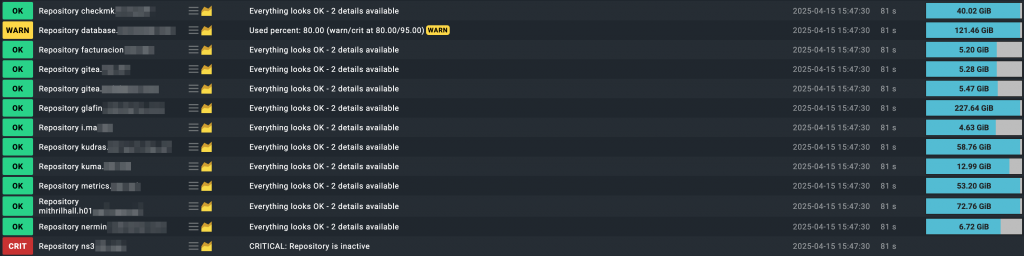
Por ejemplo, en esta captura se ve una integración real con BorgBackup, donde cada repositorio se chequea individualmente: si está activo, cuánto espacio ocupa y si ha superado los umbrales establecidos. Como puedes ver, algunos están en estado OK, otros en WARN por espacio usado, y otros en CRIT si el repositorio está inactivo. Este tipo de control fino no solo es posible con local checks, sino que además permite personalizar alertas, visualizar métricas como espacio ocupado o fecha del último backup, y automatizar la vigilancia de tareas críticas que no siempre cubren los plugins estándar de Checkmk.